I'm into pens
5 July 2022 • Pens & InkI’m into pens. There, I said it.
I’ve always had a vague, background interest in writing and writing implements. As a child, I had a couple of “teach yourself calligraphy” books, a few calligraphy pens, and I enjoyed finding excuses to use them: writing up the menu for tonight’s dinner, a sign for my bedroom door, etc. But then computers happened and I started writing by hand a lot less, and when I did, it was with whatever cheap biro happened to be close by.
Fast forward a few years (too many than I’d like to count), and in 2020 I joined the Relay FM members Discord. This was a place where people who enjoyed the variety of podcasts that Relay FM offered could socialise and discuss the topics that interested them; I joined mainly because they talked about it so much on Upgrade and Connected, and it seemed like a good place to find new people to chat with.
Turns out, I’ve made some of my best friends there. People I talk to every day, who know me better than I know some “in person” friends that I’ve known for years. But these friends have been a bad influence (on my wallet, at least).
There’s a channel in the Discord for each rough topic that the Relay FM shows cover. For example, there’s #tech, #apple, #creativity, #systems-and-themes etc. It makes sense, then, that there’s a #pens, given that there’s an entire show on Relay FM dedicated to them—The Pen Addict. I’ve listened to the show a couple of times, but it’s not one I’m subscribed to, and it never totally grabbed me. However, people sharing photos of their fountain pens, beautiful handwriting in stunning inks, letters they were writing and sending around the world—I wanted in.
I resisted for a while, I didn’t need another hobby to suck up what disposable income I had. So I started small—I asked for suggestions on a daily pen that could replace my cheap biros, nice to write with but nothing fancy. Madi suggested the Zebra Sarasa, and a three-pack dropped through the letterbox shortly afterwards. I was blown away! These were so much nicer to write with than what I’d been using before, and I was back to finding excuses to write by hand. I took to carrying one around in my pocket (a habit I’d never had before), along with a Field Notes pocket notebook that Madi had kindly sent across the ocean to me, in a package that also contained a whole host of different coloured refills. I was in.
One of the other members of the Discord, Ellen, had started up a small pen pals group, an offshoot from the official Relay Discord. I joined the group and wrote a couple of letters with the Sarasas, but really I wanted a fountain pen and everything that came with it - the little bottles of ink, the choice of nib size, the process of flushing, cleaning, and refilling, etc. So I asked for advice, took the plunge, and bought a TWSBI Eco Clear, and a bottle of TWSBI 1791 Orange ink. I mean, how else was I going to get to write in orange?!
It arrived (along with a packet of Love Hearts and the invoice held together with a little colourful smiley face paper clip, nice cute touches from Cult Pens) and I quickly filled it with the ink and started writing. Needless to say, I love it. I had chosen a medium nib, because I don’t like too skinny or too fat writing, and the only thing letting my letters down now is my handwriting!
Fast forward a few months, and I’m itching for a new colour. Don’t get me wrong, I love the orange, but I also fancied a nice vibrant pink. So what was I to do? How could I get the pink, without giving up having the orange easily to hand?
Clearly, the answer was to get a second fountain pen. (I see how this snowballs, now…) Ellen recommended another starter pen, the Lamy Safari, which I ordered in pink, with a broad nib this time. (It does need a converter to use bottled inks, as it usually takes a cartridge.) I also intended to add a bottle of Lamy Crystal ink in Rhodonite, which is a vibrant pink, but when the order arrived it turned out I’d actually somehow clicked on Agate, which is a rather flat grey. I was somewhat disappointed!
Contacting Cult Pens, they were happy for me to return the Agate and they would send out a replacement Rhodonite, which was very kind of them. I packaged the ink back up and took it off to the post office.
Ellen and another friend from the Discord, Alex, had been listening to me whine about not getting the pink, and a surprise package dropped through my letter box a day or so later. Opening it up, it contained a bottle of Robert Oster Signature ink in Hot Pink! Unbeknownst to me, they’d conspired to order me a replacement themselves, and chose Robert Oster in part because it’s good ink, but I suspect mostly because it’s Australian, and so is Ellen. They have a truly enormous range of colours, and the Hot Pink is fantastic. Exactly what I was after! It’s also in a 50ml bottle, which will last me literally forever.

However, I was still going to be getting a replacement of the Lamy Crystal Rhodonite, so I contacted Cult Pens again and asked if they could instead send out a different colour (despite Ellen’s protestations that two pinks is not too many pinks, I want a nice range of colours before I start doubling up and comparing!)
They agreed, and so we come to today: I have a TWSBI Eco (M) inked in Robert Oster Signature Hot Pink, a Lamy Safari (B) with a tiny amount of Lamy Crystal Agate, and a bottle of Lamy Crystal Amazonite (a really lovely turquoise blue) on its way. I can’t wait to try that out.
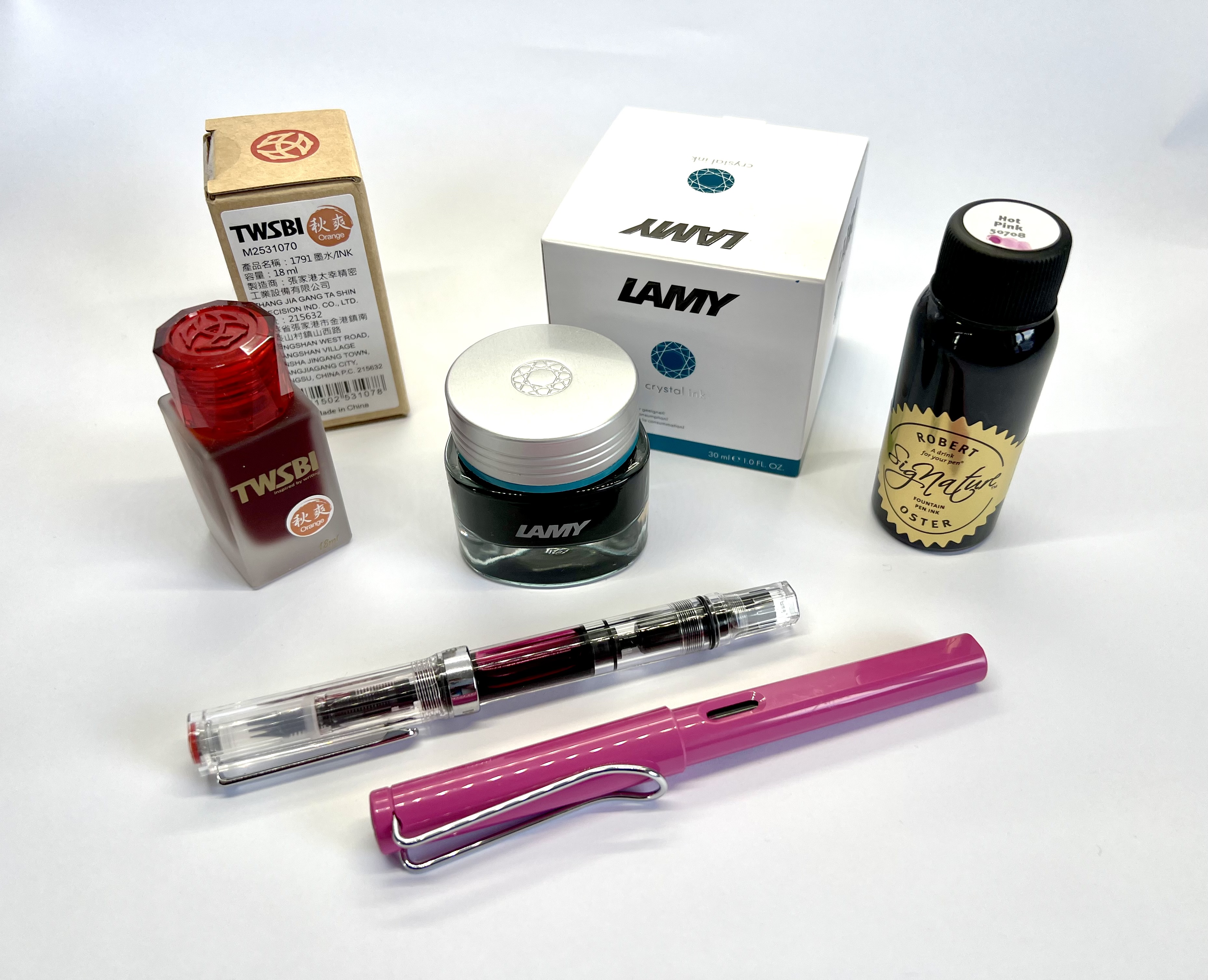
The only question is: now I have three ink bottles, and just the two pens. There’s only one solution, surely…
Python and the Magical OAuth Token
25 April 2022 • Development • PythonA recent post by Colin demonstrated a utility class they’d written to handle fetching and refreshing OAuth bearer tokens for APIs and services that are secured that way, to stop you having to worry about it in the majority of your code. For years, I’ve used a similar class at work that I wrote to simplify this, and Colin’s post prompted me to share it here too.
The main difference from Colin’s solution is that the class I use is a subclass of the Requests Session object, rather than a stand-alone object. It handles not only fetching and refreshing the bearer token where necessary, but also inserting the correct headers to the requests you make. Here’s the entire class (and a couple of helper exception classes):
import requests
import datetime
class OAuthResponseError(Exception):
pass
class OAuthInvalidGrant(OAuthResponseError):
pass
class OAuthInvalidScope(OAuthResponseError):
pass
class TokenRefreshSession(requests.Session):
ERROR_MAPPING = {
"invalid_grant": OAuthInvalidGrant,
"invalid_scope": OAuthInvalidScope,
}
def __init__(self, client_id, client_secret, scope, token_url, *args, **kwargs):
self.oauth_client_id = client_id
self.oauth_client_secret = client_secret
self.oauth_scope = scope
self.oauth_token_url = token_url
super().__init__(*args, **kwargs)
def prepare_request(self, request):
'''Add the access token to the headers'''
self.headers["Authorization"] = f"Bearer {self.oauth_access_token}"
return super().prepare_request(request)
@property
def oauth_access_token(self):
'''Return a valid Access Token. Renews the token if it has expired'''
if not self.oauth_access_token_valid():
data = {
"client_id": self.oauth_client_id,
"client_secret": self.oauth_client_secret,
"grant_type": "client_credentials",
"scope": self.oauth_scope,
}
headers = {
"Accept": "application/json",
"Content-Type": "application/x-www-form-urlencoded",
}
response = requests.post(
self.oauth_token_url,
data = data,
headers = headers,
)
response.raise_for_status()
response_data = response.json()
if "error" in response_data:
raise self.ERROR_MAPPING.get(
response_data["error"],
OAuthResponseError)(response_data["error_description"]
)
self._oauth_access_token = response_data["access_token"]
self._oauth_access_token_expiry = datetime.datetime.now() + datetime.timedelta(seconds=response_data["expires_in"])
return self._oauth_access_token
def oauth_access_token_valid(self):
'''Check the validity of the current access token'''
now = datetime.datetime.now()
fudged_time = now + datetime.timedelta(minutes=5)
access_token = getattr(self, "_oauth_access_token", None)
access_token_expiry = getattr(self, "_oauth_access_token_expiry", now)
if not access_token or access_token_expiry <= fudged_time:
return False
return True
The code is relatively simple. As a subclass of requests.Session, it accepts all the usual arguments, but also requires the OAuth client ID, client secret, scope, and token endpoint. This could be hardcoded, or a default provided in the class definition as we do internally, to avoid having to specify it each time.
The prepare_request method is part of the requests.Session mechanism for generating the HTTP call when the library is used. The overriden method in the TokenRefreshSession object inserts the correct Authorization: Bearer header and token into the request on behalf of the user.
As with Colin’s solution, the oauth_access_token property is computed when accessed, and performs the necessary update or refresh should the currently stored token have expired, by posting the client credentials data to the token endpoint provided.
Here’s an example of the class in action:
session = TokenRefreshSession(
client_id="123456",
client_secret="shh",
scope=["read", "write", "etc"],
token_url="https://api.my-great-app.com/v1.0/auth",
)
user = session.get("https://api.my-great-app.com/v1.0/users/23")
The first API call will fetch the token and store it, and subsequent calls (using the same session object) will either use the stored token or fetch a new one as necessary. You never need worry about including the Bearer header yourself. And, to quote Colin’s post:
Your token will magically manage itself, leaving you free to write good code against your favorite API.
LEGO 71374 Nintendo Entertainment System
17 August 2020 • LEGOBeyond my budget (for now!), but the new NES LEGO set looks fantastic:
71374 Nintendo Entertainment System achieves extraordinary realism, potentially surpassing any previous LEGO model in that regard. The external detail is absolutely spectacular and the designers have made splendid use of existing elements to recreate distinctive shapes from the NES. I am particularly delighted with the controller and the casing around the connection ports on the console, both of which could be mistaken for their real equivalents.
Hopefully it will be available in the LEGO employee store when I visit Billund for the 2021 Inside Tour next year!
Junos commit history: who did what?
16 November 2019 • Networking • JunosJunos has always had one fantastic advantage over Cisco’s IOS: the ability to stage a pending commit, and see a history of changes, rather than each command immediately being executed on the running config a soon as you hit Enter.
The show | compare rollback X command has always been able to show you the difference between your current config and what the config was like X commits ago. However, I’ve always found it difficult to figure out what exactly was done in a single commit (or batch of commits) if they weren’t the most recent. That is, until I learnt of this command: show system rollback compare X Y! This lets you see the changes that were introduced just between the X and Y commits.
Here’s a real life example. Below is the commit history for a device at work. You can see there were a number of batches of commits going back in time where different individuals have done sole changes on the device:
ben@switch> show system commit
0 2019-11-13 15:06:51 GMT by katerina via cli
1 2019-11-13 14:49:19 GMT by katerina via cli
2 2019-11-13 14:43:01 GMT by katerina via cli
3 2019-11-13 14:42:11 GMT by katerina via cli
4 2019-11-13 14:41:01 GMT by katerina via cli
5 2019-11-13 14:03:53 GMT by katerina via cli
6 2019-11-13 12:28:33 GMT by katerina via cli
7 2019-11-13 12:25:44 GMT by katerina via cli
8 2019-11-13 12:24:53 GMT by katerina via cli
9 2019-11-13 12:23:28 GMT by katerina via cli
… output truncated …
20 2019-09-13 14:16:43 BST by ben via cli
21 2019-09-13 14:15:27 BST by ben via cli
22 2019-09-13 14:13:48 BST by ben via cli
23 2019-09-13 14:13:06 BST by ben via cli
24 2019-09-13 14:08:43 BST by ben via cli
25 2019-09-13 14:08:13 BST by ben via cli
26 2019-09-13 14:06:50 BST by ben via cli
27 2019-09-13 14:06:12 BST by ben via cli
28 2019-08-07 14:21:33 BST by stuart via cli
29 2019-08-07 14:21:08 BST by stuart via cli
30 2019-08-07 14:18:43 BST by stuart via cli
31 2019-08-05 09:06:28 BST by stuart via cli
32 2019-06-19 13:04:54 BST by lewis via cli
33 2019-06-19 13:02:34 BST by lewis via cli
34 2019-06-19 13:01:31 BST by lewis via cli commit confirmed, rollback in 3mins
35 2019-06-19 12:59:30 BST by lewis via cli
36 2019-06-19 12:58:39 BST by lewis via cli
37 2019-06-19 12:58:03 BST by lewis via cli commit confirmed, rollback in 3mins
38 2019-06-07 13:58:39 BST by bart via cli
39 2019-06-07 13:07:17 BST by bart via cli commit confirmed, rollback in 1mins
40 2019-06-06 12:27:51 BST by bart via cli
41 2019-05-15 13:07:07 BST by chris via cli
42 2019-05-09 14:14:43 BST by chris via cli
I needed to find what Stuart and Lewis had each introduced in their batches of changes back in August and June, respectively. This new command makes that trivially easy.
Stuart’s batches of changes were in commits 28–31. Running the following command, I was able to easily extract just what those commits introduced:
ben@switch> show system rollback compare 32 28
[edit interfaces interface-range ir_stp_edge]
member ge-0/0/10 { ... }
+ member ge-0/0/6;
+ member ge-0/0/7;
+ member ge-0/0/8;
… more changes …
Note that you need to put the higher (older) commit number first, followed by the lower (more recent). Additionally, you need to increase the higher commits number by one, as you want to know what was introduced between those commits, including the oldest one.
Likewise, to see what Lewis introduced in his commits, we can run the following:
ben@switch> show system rollback compare 38 32
… some changes ...
This will definitely save me some time in future!
Tiny Git Tip
10 October 2019 • Development • Tip • GitBrandur, on Twitter:
Git tip I wish I’d discovered ten years ago: if you
git config --global diff.noprefix trueit removes the sillya/andb/prefixes so that when you double-click select one to copy, you get a usable filename instead of a mangled path.
This is something I’ve always been annoyed by—I’m so glad there’s a fix!
NASA Administrator Remembers Mission Control Pioneer Chris Kraft
23 July 2019 • SpaceChris Kraft, NASA’s first Flight Director, died yesterday, two days after the 50th anniversary of the first man on the moon.
Once comparing his complex work as a flight director to a conductor’s, Kraft said, ‘The conductor can’t play all the instruments–he may not even be able to play any one of them. But, he knows when the first violin should be playing, and he knows when the trumpets should be loud or soft, and when the drummer should be drumming. He mixes all this up and out comes music. That’s what we do here.’
It’s almost as if he waited for the anniversary. The world remembers the names of the men who set foot on the moon, but Chris Kraft was another hugely important person managing the hundreds of highly skilled engineers and scientists without whom the moon landing would not have been possible.
We’re fast approaching a time where there will be nobody left who was involved in project Apollo. It will never be forgotten, but it will be sad to no longer be remembered first hand.
Self-Host Your Static Assets
11 July 2019 • Development • WebHarry Roberts, writing at CSS Wizardry:
One of the quickest wins—and one of the first things I recommend my clients do—to make websites faster can at first seem counter-intuitive: you should self-host all of your static assets, forgoing others’ CDNs/infrastructure. In this short and hopefully very straightforward post, I want to outline the disadvantages of hosting your static assets ‘off-site’, and the overwhelming benefits of hosting them on your own origin.
I’m a little late to this (the post was written back in May), but it’s an interesting counter argument to the common practice of serving third party resources from a provider’s CDN. The post goes into a lot more detail, but if you can, host it yourself.
The Two-Napkin Protocol
7 July 2019 • Networking • BGPAn interesting piece of history I didn’t previously know.
It was 1989. Kirk Lougheed of Cisco and Yakov Rekhter of IBM were having lunch in a meeting hall cafeteria at an Internet Engineering Task Force (IETF) conference.
They wrote a new routing protocol that became RFC (Request for Comment) 1105, the Border Gateway Protocol (BGP), known to many as the “Two Napkin Protocol” — in reference to the napkins they used to capture their thoughts.
The post is worth a read just to see the photos of the napkins. I’ve never really thought before about how RFCs come to be. I’d always assumed they were the result of clever people in offices, not really thought up on the back of a napkin over drinks!
Also, as it’s 2019… happy 30th birthday, BGP (and the World Wide Web).
The Infrastructure Mess Causing Countless Internet Outages
29 June 2019 • Networking • BGPRoland Dobbins from Netscout Arbor, quoted in this Wired article:
“Nonspecialists kind of view the internet as this high-tech, gleaming thing like the bridge of the starship Enterprise. It’s not like that at all. It’s more like an 18th-century Royal Navy frigate. There’s a lot of running around and screaming and shouting and pulling on ropes to try to get things going in the right direction.”
It’s amazing how fragile some of the technologies that power something the world takes for granted are; BGP is a great example of that. The Internet is everywhere, and it’s becoming increasingly more necessary to be connected in order to be able to just go about our lives.
Regarding the choice of headline, however, I don’t think the word “mess” is fair. That does a disservice to the hundreds of very talented people that design, implement, and maintain the infrastructre that underpins our connected world.
Junos: Confirm a commit cleanly"
27 July 2018 • Networking • JunosFor years, I have loved the fact that Junos allows you to perform a commit confirmed to apply the configuration with an automatic rollback in a certain number of minutes.
I have always believed that the only way to confirm the commit (i.e. stop the automatic rollback) was to commit again. This creates two commits in the commit history, one containing the actual config diff, and an empty one purely used to stop the rollback. I’ve always thought that this creates a somewhat messy commit history, and confuses the use of show | compare rollback:
{% highlight bash %} [edit] ben@device> run show system commit 0 2018-07-27 08:44:26 BST by ben via cli 1 2018-07-27 08:44:07 BST by ben via cli commit confirmed, rollback in 5mins 2 2018-07-23 10:04:29 BST by ben via cli 3 2018-07-23 10:03:58 BST by ben via cli commit confirmed, rollback in 2mins
[edit] ben@device> show | compare rollback 1
[edit] ben@device> # Huh, it’s empty?! I’m sure I did some work…
[edit] ben@device> show | compare rollback 2 [edit system] - host-name old-device + host-name device
[edit] ben@device> # Oh, there it is…
However, today I learnt that a commit check is enough to stop the rollback, and doesn’t create an empty commit! My commit histories are now much cleaner, and show | compare rollback commands a lot easier to work out what you’re actually looking at.
{% highlight bash %} [edit] ben@device> run show system commit 1 2018-07-27 08:44:07 BST by ben via cli commit confirmed, rollback in 5mins 3 2018-07-23 10:03:58 BST by ben via cli commit confirmed, rollback in 2mins
[edit] ben@device> show | compare rollback 1 [edit system] - host-name old-device + host-name device
Much better!